Stack Labs Blog moves to Dev.to | Le Blog Stack Labs déménage sur Dev.to 🚀
A la découverte de l'analyse de sentiment

Temps de lecture estimé : 9 minutes
L’analyse de sentiment est un domaine de recherche en Traitement Automatique du Langage (NLP : Natural Language Processing) qui a reçu beaucoup d’intérêt ces dernières années. Cet intérêt toujours croissant est sans doute porté par le grand nombre d’applications qu’on peut avoir dans des domaines très variés. Dans cet article, je vais définir ce qu’est l’analyse de sentiment, présenter les différents niveaux de granularité et les différentes applications qu’on peut avoir, et enfin détailler les principales méthodes utilisées (des méthodes non supervisées aux réseaux de neurones récursifs et word embeddings spécifiques).
L’analyse de sentiment, qu’est-ce que c’est ?
L’analyse de sentiment, appelée aussi analyse d’opinion, est la tâche qui permet d’analyser le sens affectif et/ou subjectif véhiculé dans un texte donné. Le plus souvent, le terme “analyse de sentiment” est utilisé pour désigner la tâche de classification automatique de texte en fonction de la polarité exprimée (positive, négative ou neutre). Cependant, il couvre en réalité un plus grand nombre de tâches relatives à la détection de l’attitude générale de l’auteur du texte à l’égard d’une cible particulière. Cette attitude peut être observée à travers :
- La polarité : est-ce que le texte exprime un sentiment positif, négatif ou neutre.
- La subjectivité : est-ce que le texte exprime une information objective ou est-ce qu’il donne une opinion subjective.
- L’émotion précise : Joie, tristesse, colère, peur, etc. Plusieurs typologies existent dont les plus connues sont celles d’Ekman (6 émotions) et de Plutchik (8 émotions).
- L’intensité : parfois catégorielle (par exemple un entier entre 0 et 5 étoiles) mais le plus souvent numérique (par exemple un réel entre 0 et 1 par exemple).
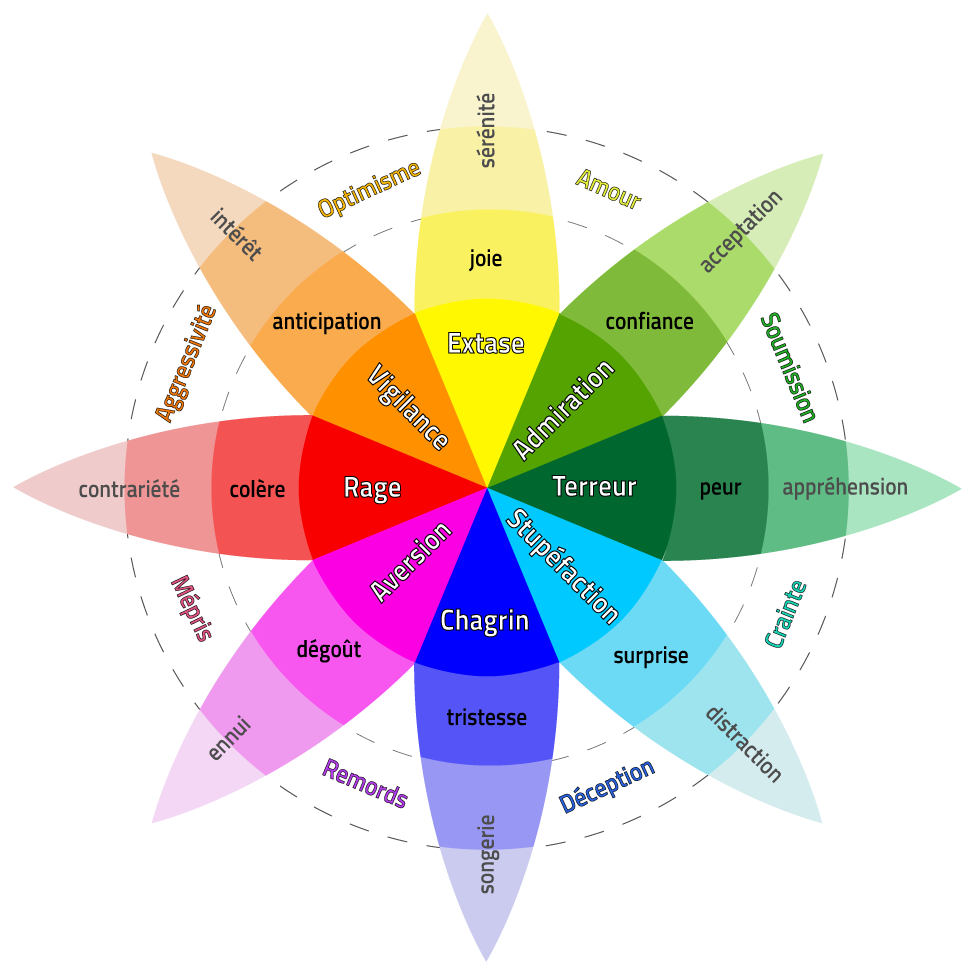
La roue des émotions de Plutchik ci-dessous distingue 8 émotions de bases avec 3 niveaux d’intensité catégorielle :
Plusieurs niveaux de granularité
L’attitude de l’auteur d’un texte peut être aussi observée sur plusieurs niveaux de granularité :
- Niveau document : la majorité des méthodes de classification de sentiments s’applique à l’ensemble du texte qu’il soit court ou long (tweet, commentaire, etc.).
- Niveau phrase : parfois on souhaite analyser le sentiment exprimé dans chaque phrase pour les documents longs (compte rendu de débat parlementaire, etc.).
- Niveau entité cible : dans la même phrase il est possible d’exprimer une opinion positive sur une entité particulière et une opinion négative sur une autre entité. Par exemple : “Obama était un excellent président, Trump est tout le contraire”.
- Niveau aspect : dans la même phrase il est possible d’exprimer une opinion positive sur un aspect de l’entité et une émotion négative sur un autre autre aspect de la même entité. Par exemple : “L’appareil photo du nouvel iPhone est vraiment super, mais la batterie tient moins longtemps”.
Si la majorité des méthodes proposées dans la littérature concerne les niveaux document et phrase, l’interêt pour le niveau cible et aspect est de plus en plus croissant. Seulement, cela rend la tâche encore plus compliquée puisqu’il ne suffit plus de détecter le sentiment mais il faut de plus le relier à une entité ou à un aspect de l’entité (qu’il faut aussi détecter au préalable !).
Les applications
Les applications de l’analyse de sentiment sont vraiment nombreuses et variées. Pour avoir une liste assez exhaustive des applications qu’on peut avoir, je vous reccomande de jeter un coup d’oeil sur le livre de Bo Pang, Senior Research Scientist chez Google. A titre d’exemple, je peux en citer ici quelques-unes :
- La classification des avis clients sur un produit particulier exprimés un peu partout sur le web.
- Le suivi de l’évolution de l’opinion sur un sujet donné : un projet de loi, une personnalité politique, etc.
- La détection des messages / posts incitant à la haine sur les réseaux sociaux.
- Le calcul de la réputation des utilisateurs sur la base des sentiments et opinions exprimés dans les messages qui leur sont adressés.
- La prévention du suicide par l’analyse des publications des utilisateurs sur réseaux sociaux.
- La classification des emails reçus pour la ré-orientation au service concerné ou pour la détection de la priorité de l’email.
- etc.
Les méthodes utilisées
Dans cette section, je vais présenter les principales méthodes utilisées pour la classification de sentiment (polarité, émotion, etc.) au niveau du document ou de la phrase.
Les lexiques
Les sentiments et les opinions sont exprimés par des mots (”content”, “triste”, “déçu”, etc.). C’est la raison pour laquelle les premiers travaux ont essayé de construire des lexiques de sentiment ou d’émotion qui associent chaque mot à un sentiment et / ou à une ou plusieurs émotions. Les méthodes de construction de ces lexiques peuvent être :
- Manuelles : les plateformes de crowdsourcing peuvent être utilisés à cet effet comme CloudFlower ou Amazon Mechanical Turk.
- Automatiques : par exemple en utilisant des corpus de textes annotés et en cherchant les mots qui apparaissent souvent dans les documents positifs et ceux qui apparaissent souvent dans les documents négatifs (on peut utiliser des mesures d’information mutuelles comme la PMI: Pointwise Mutual Information).
- Semi-automatique : en partant par exemple d’une petite liste de mots annotés et en appliquant des techniques de bootstrap pour agrandir cette liste.
Peter Turney était l’un des premiers à s’intéresser à l’analyse de sentiment en publiant en 2002 un article sur la classification de texte selon le sentiment exprimé. L’approche proposée consiste à calculer l’orientation sémantique des adjectifs et des adverbes de chaque texte. Ce n’est rien d’autre que l’information mutuelle entre chaque terme et le mot “excellent” moins l’information mutuelle entre le terme et le mot “mauvais”. Chaque commentaire est ensuite recommandé ou non en fonction de l’orientation sémantique moyenne de tous ses termes.
Ce genre de méthodes a l’avantage de ne pas nécessiter de données d’apprentissage, mais il a été prouvé à travers différentes campagnes d’évaluation que les méthodes supervisées donnaient de meilleurs résultats.
L’apprentissage supervisé
La majorité des méthodes actuelles d’analyse de sentiment apprennent des modèles de classification supervisée. Ces méthodes nécessitent des données d’apprentissage contenant au moins plusieurs milliers de textes annotés (le text brut + le sentiment ou l’opinion qu’il exprime). L’approche générale était d’apprendre des modèles de Machine Learning comme le Naive Bayes, le Random Forrest ou les Support Vector Machines (SVM) sur des représentations en Bag Of Words. Il s’agit de transformer le texte brut non structuré en un format structuré où chaque ligne représente un document (un tweet ou une phrase) et où chaque colonne représente un mot. La représentation qui donne en général les meilleurs résultats est la représentation booléenne où chaque cellule recevra la valeur 1 si le mot apparaît dans le texte et 0 sinon. En plus des mots utilisés dans le corpus d’apprentissage, un gros effort de “features engineering” permet d’améliorer les résultats. On pourrait construire différentes features pertinentes pour cette tâche de classification en se basant sur l’utilisation des émotions, de lettres répétées, de la ponctuation, des majuscules, etc.
Lors de la campagne d’évaluation Sem-Eval 2013, Saif Mohammad du National Research Council Canada a participé avec un système considéré à l’époque comme l’état de l’art de l’analyse de sentiment. Il s’agit d’un SVM appris sur du Bag Of Words (n-grammes de mots), des features linguistiques (émotions, ponctuations, lettres répétées, etc.) et des features lexicales construites à partir de lexiques de sentiments (nombre de mots positifs selon le lexique, nombre de mots exprimants des sentiments négatifs, etc). Le système s’est classé premier sur 44 équipes participantes pour la classification de tweets rédigés en anglais suivant le sentiment exprimé.
L’équivalent français de la compétition Sem-Eval s’appelle DEFT pour Défi de Fouille de Texte. Ce défi organisé chaque année a consacré plusieurs éditions à l’analyse de sentiment et à l’analyse d’opinion. En 2015, j’ai moi-même participé avec un SVM hyper “tunné” appris sur des n-grammes de mots et pleins d’autres features linguistiques et lexicales. Le système s’est classé premier pour la classification des tweets français selon leur subjectivité et troisième pour la polarité.
L’âge d’or du word embedding
Si l’approche Bag of Words combinée à du features engineering permet d’obtenir de très bons résultats, la communauté n’a pas résisté longtemps avant de se laisser tenter par les approches basées sur les réseaux de neurones et le fameux “Word Embedding” (ou prolongement de mots). Bien qu’il s’agisse toujours d’une approche supervisée et que l’on utilisait des réseaux de neurones depuis longtemps pour nos tâches de classification, les nouvelles approches ne partent plus d’une représentation de tout le document mais d’une représentation du mot. La promesse était qu’avec ce genre d’approches on allait enfin pouvoir se séparer de l’effort de feature engineering et laisser le réseau construire par lui-même les différentes abstractions sémantiques qui vont l’aider à faire la classification.
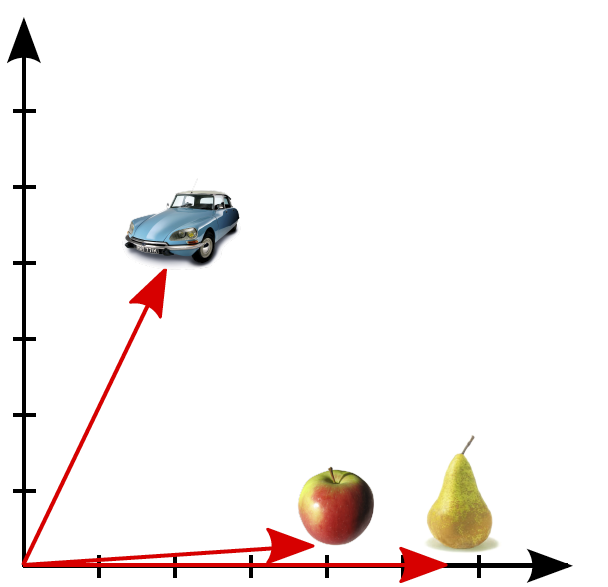
Tout a commencé en 2013, lorsque Thomas Mikolov de Google a proposé, au travers de quelques publications et de son outil Word2Vec, une nouvelle façon de structurer les données textuelles. L’idée est de représenter chaque mot par un vecteur de dimension fixe qui va en quelque sorte capturer son sens. L’hypothèse est que les mots qui apparaissent souvent avec les mêmes contextes sont probablement proches d’un point de vue sémantique. En lisant des phrases aléatoires sur internet, on pourrait tomber par exemple sur les phrases suivantes :
- “La pomme est un fruit”
- “La poire est un fruit”
- “La voiture est un moyen de transport”
On saurait donc que les mots pomme et poire sont sémantiquement plus proches que pomme et voiture ou que poire et voiture. Le vecteur qui va représenter le mot pomme devrait donc être plus proche du vecteur du mot poire que du vecteur du mot voiture. En présentant les vecteurs de ces trois mots sur deux dimension, on devrait voir une figure qui ressemble à celle-ci.
Le word embedding présente une nouvelle façon de structurer les données textuelles qui est adaptée à l’utilisation des réseaux de neurones. Plusieurs familles de réseaux de neurones ont été proposées et utilisées pour des tâches de classification de textes (et donc aussi de classification de sentiment). Les plus connus sont probablement les réseaux récurents adaptés aux données séquentielles (texte, série temporelle, etc.) et les réseaux convolutifs qui sont souvent utilisés dans la vision mais qui commencent à faire leurs preuves sur le texte.
En 2014, Duyu Tang a proposé dans sa thèse d’apprendre des word embeddings spécifiques aux sentiments. Il a collecté environ 10 millions de tweets contenant des émoticones positifs ou négatifs. Ce corpus lui a permis d’apprendre des prolongements de mots basés à la fois sur le contexte mais aussi sur le sentiment global du tweet. En 2015, Tang a proposé d’apprendre un réseau de neurone récursif de type GRU (Gated Recurrent Unit) pour la classification de sentiment. A partir de 2016, les réseaux de neurones profonds commencent à dominer le classement des campagnes d’évaluation Sem-Eval et DEFT qu’ils soient basés sur des word embeddings génériques ou spécifiques.
Bien que le sujet soit né depuis plus de 15 ans, l’interêt pour l’analyse de sentiment ne cesse de croître. Alors si le domaine vous passionne, n’hésitez pas à vous lancer aujourd’hui car ce domaine passionnant a encore de l’avenir !
Ressources utiles
- Un lexique de sentiment et d’émotion pour la langue française.
- Plusieurs lexiques de sentiment et d’émotion pour l’anglais.
- Les datasets et les résultats des campagnes d’évaluation francophones DEFT.
- Une étude de Bo Pang sur l’analyse de sentiment.
- Un tutoriel simple pour apprendre votre premier modèle de classification de sentiment.