Stack Labs Blog moves to Dev.to | Le Blog Stack Labs déménage sur Dev.to 🚀
Terraform: Comment déployer facilement une infrastructure en quelques commandes

Temps de lecture estimé : 12 minutes
Aujourd’hui au menu, Terraform : un outil sympathique qui permet de gérer de l’infrastructure-as-code indépendamment du Cloud que vous utilisez !
Déployer une infrastructure à la main, ça va de “pénible et long” à “carrément diabolique”.
Admettons, votre architecte Cloud a mis ses trois dernières semaines de travail à faire une architecture aux petits oignons et vous tend un magnifique schéma. “Tu peux me déployer ça, s’il-te-plaît?”. Vous regardez le schéma… Des VPC dans tous les coins, assez d’instances EC2 pour gagner sa vie en minant de la cryptomonnaie et ne parlons même pas des lambdas !
Non, définitivement, déployer une architecture à la main, c’est inefficace, pas très agréable pour la personne qui le fait et source d’erreur humaine.
Chacun des grands cloud providers fournit une solution de déploiement automatisé, c’est-à-dire d’infrastructure-as-code. L’intérêt est simple : écrire une série de fichiers descriptifs des différents éléments de l’infrastructure, dits templates, la donner à manger à la solution de déploiement automatisé qui déploie alors une infrastructure respectant exactement les spécifications données dans les templates.
Cela dit, que vous utilisiez CloudFormation (AWS), Deployment Manager (GCP), ou Azure Resource Manager (Azure), vous devez développer un template particulier pour chacun de ces outils. Heureusement, Terraform est là pour proposer une solution de déploiement unifiée !
Infrastructure-as-code indépendante du cloud
Mais si je n’utilise qu’un seul provider, pourquoi est-ce que je prendrais Terraform?
Il y a, à mes yeux, une myriade de raisons d’utiliser Terraform. La première et une des plus importante est qu’il répond à un besoin réel, et y répond bien. Terraform est un outil multi-cloud : passer d’un déploiement sur AWS à un déploiement sur, par exemple GCP, est faisable en s’inspirant des templates version AWS, réduisant ainsi la charge de travail comparée avec une réécriture ex-nihilo. L’infrastructure ainsi décrite peut être portée sur d’autres plateformes, un peu à la manière du lift-and-shift, en reprenant et en s’inspirant des templates et en les “traduisant”.
De surcroît, une fois le déploiement terminé, Terraform établit un fichier .tfstate. Ce dernier permet à Terraform de facilement reprendre l’état actuel de l’infrastructure et le mettre à jour pour lancer d’autres opérations dessus. Contrairement aux services d’infrastructure-as-code des grandes plateformes de cloud computing, il est requis d’avoir un dossier Terraform en local sur un ordinateur pour exécuter des créations et destructions d’infrastructures, ainsi que des clés d’accès à un utilisateur avec suffisamment de permissions. Après, il est tout à fait possible de stocker les templates et le .tfstate dans le cloud, lorsqu’ils ne servent pas, ou juste pour avoir un backup. On peut également recommander de push le .tfstate avec l’intégralité des fichiers Terraform sur un repo git pour permettre à tout le monde de faire des mises à jour et des modifications sur l’infrastructure déployée.
Un autre avantage est celui de pouvoir voir un rapport prévisionnel du déploiement avant de lancer le vrai déploiement et pendant ce dernier, Terraform affiche également sa progression de manière répétée et détaillée dans le terminal.
Enfin, la documentation fournie par HashiCorp, l’éditeur de Terraform, est très complète, sans compter la quantité impressionnante de fournisseurs de services disponibles. Bref, Terraform est un petit couteau suisse pratique.
Les commandes de base
Initialiser un dossier Terraform
Terraform s’initialise dans un dossier, au choix. C’est le dossier dans lequel il faudra placer l’intégralité des templates avec lesquelles Terraform va travailler. La commande qui effectue cette action est :
$ terraform init
Si Terraform trouve des fichiers au bon format, à savoir .tf pour les templates Terraform, il va initialiser un sous-dossier masqué .terraform dans lequel seront téléchargés les plugins pour le provider sélectionné. Nous allons maintenant voir comment choisir ce provider.
Il est tout à fait possible, avec Terraform, de mettre toute son infrastructure dans un seul fichier .tf. Cependant, pour plus de lisibilité, il est agréable de les trier par type ou par service. Créons donc un ficher provider.tf :
Ce fichier sert à dire à Terraform ce que l’on utilise. La syntaxe Terraform ressemble à un croisement entre JSON et YAML, ce qui la rend assez facile à lire et écrire par des humains. L’on notera que Terraform accepte aussi le JSON.
Ici, on demande à Terraform de télécharger le plugin pour gérer des ressources AWS. La variable “profile” sert à indiquer le profil nommé (voir named profiles sur l’AWS CLI) qui sera utilisé pour lancer les commandes (Si vous comptez déployer quoi que ce soit au cours de cet article, pensez à mettre un nom de profil valide). La région spécifiée correspond à la région dans laquelle sera déployée l’infrastructure.
Terraform télécharge donc le plugin et le place dans .terraform. Comme le plugin est assez lourd, il est recommandé d’éviter de le télécharger à répétition et d’éviter de le mettre sur un repo git.
Cette étape peut être effectuée avec ou sans d’autres fichiers .tf. Seuls les blocs “provider” sont lus pour l’initialisation. Il est possible d’en mettre plusieurs à la suite pour interagir avec différentes plateformes.
Notre première infrastructure : un bucket s3
Créons maintenant notre premier objet AWS avec Terraform : un bucket s3 et mettons-y une photo de mon chat ! Pour cela, créons un fichier s3.tf. Une fois de plus, rien (mis à part l’esthétique et la lisibilité) ne nous empêche de le mettre dans le même fichier que le bloc “provider”, mais mieux vaut ranger son espace de travail.

Décomposons un peu ce fichier. Deux ressources sont crées avec le mot-clé “resource”. La première est un “aws_s3_bucket”, donc le bucket que nous allons créer. Son nom, pour Terraform, est “my-bucket-example”. Cependant, son paramètre “bucket” est déclaré comme étant “my-bucket-example-23413426676567”. Ceci est dû au fait que les noms des buckets sont uniques. Ceci est le nom du bucket qui sera créé sur notre compte AWS. Le nom donné à la ressource pour Terraform n’est utilisé que par Terraform. Le paramètre “acl” ou “access control list” nous permet de choisir qui peut accéder à ce bucket. Par défaut, le bucket est privé, mais comme j’adore mon chat, nous allons le rendre lisible au public.
La deuxième ressource définie correspond à l’image de chat que l’on veut placer dans le bucket, au préalable téléchargée et placée dans le même dossier. Évidemment, il est possible de la placer ailleurs et de modifier le paramètre “source” en conséquence. Prêtons une attention toute particulière au paramètre “bucket”. En effet, nous aurions pu mettre “my-bucket-example-23413426676567”. Cependant, dans le cas où le nom du bucket est variable, il est possible d’y faire référence par son nom Terraform, dans ce cas, sans quotes, ce qui permettra à Terraform de trouver le bon nom du bucket pendant le déploiement. Cette résolution de nom s’appelle une référence (voir partie “Références”).
Il est maintenant temps de déployer cette infrastructure ! Commençons par demander à Terraform de nous faire un petit rapport sur ce qu’il va faire. Pour cela, exécutons :
$ terraform plan
Terraform nous propose donc une liste ordonnée de tout ce qu’il veut faire. Ceci peut être pratique pour nous rappeler à quoi servaient ces fichiers sans avoir besoin de relire les templates. La commande qui nous intéresse est la suivante :
$ terraform apply
Cette dernière génère le même plan que terraform plan, mais nous demande ensuite confirmation pour déployer l’infrastructure. Lorsqu’on la lui donne, Terraform crée alors les ressources et nous donne le temps requis pour les mettre en place.
Il est ensuite possible de voir notre photo de chat sur le bucket, soit en visitant l’adresse donnée, soit en allant voir directement sur la console AWS.
Lors de la création des ressources, Terraform a créé un fichier terraform.tfstate. Ce fichier traque l’intégralité des ressources gérées par Terraform. Avant chaque opération, Terraform va actualiser le .tfstate. Il est aussi possible de lui faire actualiser le .tfstate manuellement, ainsi que de faire rentrer des ressources créées autrement dans le .tfstate, ce qui permettra à Terraform de les gérer, bien qu’elles n’aient pas été créées avec un template.
Relancer la commande terraform apply permet de comparer l’état actuel de l’infrastructure (mis à jour et enregistré dans le .tfstate) à celui décrit dans le template. Si les deux sont identiques, Terraform se contentera de ne rien faire. Sinon, il proposera de faire correspondre l’infrastructure existente à celle décrite par le template.
Enfin, pour détruire ce bucket (je me doute que vous aimez aussi mon chat, mais vous n’allez pas garder la photo dessus quand-même), il nous reste simplement à lancer :
$ terraform destroy
Une fois le .tfstate mis à jour, Terraform demande confirmation et, le cas échéant, détruit l’infrastructure enregistrée. Vous connaissez désormais la base de l’utilisation de Terraform !
Un exemple complet sur AWS
L’exemple précédent illustrait une utilisation simple des templates de Terraform pour déployer un objet quelconque. Nous allons maintenant nous plonger dans une infrastructure plus complexe afin de couvrir un cas applicable.
Template de base
Considérons la demande d’infrastructure suivante :
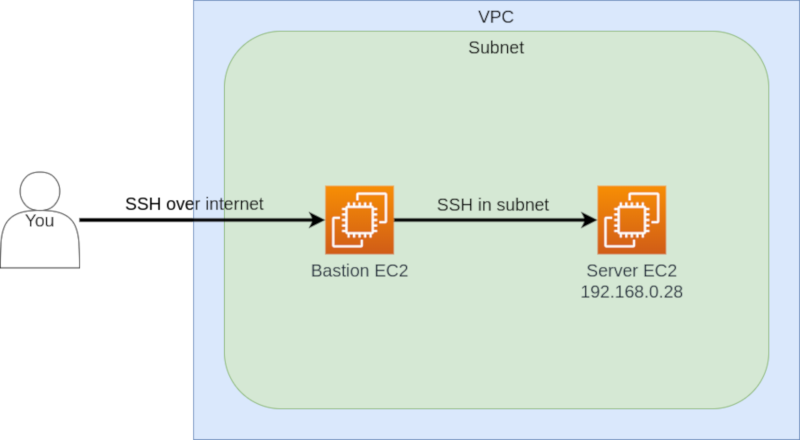
On veut donc créer un VPC et un premier subnet dans lequel on placera deux instances : un “bastion” avec une adresse IP externe dans lequel on pourra se connecter en SSH et un serveur privé auquel on accède depuis le bastion.
Commençons par créer les composants du plus général au plus fin. Les templates vont être assez longues, pour le coup, parce qu’elles créent tout ce qu’il faut pour. En langage Terraform, un commentaire se marque avec #. Créons donc vpc.tf avec des commentaires explicatifs. Jusqu’à ce que l’on se mette à parler d’un autre fichier, tous ces blocs vont ensemble dans vpc.tf.
Ouf ! C’était fastidieux ! Heureusement, on ne crée pas des VPC tous les jours. Et généralement, les paramètres changent peu. Attaquons-nous maintenant aux instances EC2. Créons donc ec2.tf :
Ouf ! Voilà, l’intégralité de l’infrastructure est déployée. Mais il reste certaines choses qui ne sont pas réglées : il nous faut parler plus en détails des références, aborder les variables (rappelez-vous le ${var.ip} de tout à l’heure) et enfin, récupérer certaines valeurs à la fin du déploiement.
Références, variables, outputs
Références
Nous avons déjà parlé précédemment des références. En quelques mots, une référence est la valeur d’un paramètre fixe d’une autre ressource. Elle s’écrit selon une structure un peu “orientée-objet”, c’est-à-dire qu’on écrit <type de la ressource>.<nom Terraform de la ressource>.<valeur recherchée>. On peut écrire une référence seule sans guillemets, directement dans le template, comme vu précédemment. Par exemple, écrire subnet_id = "aws_subnet.my-vpc-subnet.id" est redondant dans Terraform v0.12.20.
Cependant, ceci n’est vrai que pour les références “seules”. Si une référence est mixée à d’autres caractères, il faut utiliser la structure de variable de Terraform, c’est-à-dire la suivante :
"Resource": "${aws_s3_bucket.my-bucket.arn}/*"
On trouverait ce type de strucure dans une policy IAM, par exemple, où l’on voudrait restreindre l’accès en lecture d’un utilisateur à “my-bucket”.
Puisque la ligne ne se compose pas exclusivement d’une référence, on encadre la référence telle une variable, c’est-à-dire que toute la chaîne de caractères doit être entre guillemets et la référence doit être encadrée par ${}, comme les variables, dont nous allons parler maintenant.
Variables
Supposons que, pour savoir à qui est quelle ressource, nous voulons créer un tag “Nom” attaché à chaque ressource qui est la concaténation du nom Terraform de la ressource et du profil AWS utilisé pour le déployer. Pour éviter de devoir modifier les fichiers à chaque fois, optons pour l’utilisation d’une variable !
Une variable se déclare généralement dans variables.tf. Il est possible de lui attribuer une valeur par défaut et d’en passer une en paramètre à terraform plan, terraform apply ou terraform destroy.
Inclure ce fichier permet à Terraform d’interpréter, lors de terraform plan, terraform apply ou terraform destroy, l’instruction "${var.profile}" comme une valeur passée en paramètre, ou sinon, comme “default”. Pour passer une valeur en paramètres, on utilise :
$ terraform apply -var="profile=my-profile"
On peut alors ajouter le bloc suivant à n’importe quelle ressource :
La variable est ainsi concaténée avec le nom de notre choix et peut être changée pour chaque déploiement. Évidemment, il est possible d’écrire autant de blocs variable "" {} que voulu. On dispose également d’une variable “ip” qui sert à écrire le security group et s’assurer que nous seuls pouvons accéder à notre instance.
Outputs
Il est également intéressant de récupérer certaines valeurs attribuées lors du processus de déploiement. Tout ceci est faisable sans avoir besoin de faire des appels à l’API de AWS. En effet, c’est ce à quoi sert un fichier output.tf ! Dans notre cas, nous voulons récupérer l’adresse IP publique du bastion que nous avons créé. Voyons donc sa structure de base :
Une fois l’output déclaré, Terraform l’affichera de lui-même après un terraform apply. Pour cela, on peut utiliser la commande $ terraform output bastion-ip pour obtenir directement la valeur dans notre shell, voire pour l’assigner à une variable locale. Évidemment, il est possible d’écrire autant de blocs output "" {} que voulu.
Voilà une sacrée aventure. Nous pouvons donc placer tous ces fichiers Terraform (provider.tf, vpc.tf, ec2.tf, variables.tf, output.tf) dans un même dossier, avec la clé SSH générée précédemment. A partir de là :
$ terraform apply -var="profile=$YOUR_PROFILE" -var="ip=$YOUR_IP"
Il vous sera demandé de confirmer le déploiement. Une fois que celui-ci est terminé, l’IP publique du bastion sera affichée. A partir de là :
scp -i key ./key ec2-user@$BASTION_IP:/home/ec2-user
ssh -i key ec2-user@$BASTION_IP
ssh -i key ec2-user@192.168.0.28
cat hello.txt
On peut donc bien accéder à nos deux instances et l’on retrouve bien le fichier que l’on a créé à l’aide du script de lancement.
Voilà ! Vous avez maintenant une bonne idée de comment créer une infrastructure de base avec Terraform, que cela soit dans un VPC créé pour l’occasion, ou en utilisant votre propre VPC.
La dimension multi-cloud
Intéressons-nous maintenant à la possibilité de changer de fournisseur en “adaptant” un template existant en un autre. Évidemment, l’adaptation d’un template à un autre fournisseur est une opération unique à chaque infrastructure et dépendant fortement des deux fournisseurs de services impliqués. Nous allons donc aborder un cas général.
Abordons donc un petit exemple de ce qui rend Terraform si intéressant pour le multi-cloud. Intéressons-nous à l’aide de Terraform pour les bucket S3 de AWS et pour les bucket Cloud Storage de GCP.
Terraform supporte une variété de blocs pour ces deux objets. Ces blocs sont souvent identiques, par exemple website, versioning, cors, lifecycle_rule, logging. Prenons l’exemple d’un bucket sensé servir de site web statique.
Pour des fonctionnalités simples, les deux templates sont largement similaires. Évidemment, dès lors que l’on rentre dans des fonctionnalités plus complexes, les descriptions divergent. Cela dit, pour une bonne partie du template, il est facile de créer un script ou parseur pour “traduire” un template AWS en template GCP, ou vice versa, même si finalement, le changement reste non-trivial.
Conclusion
Vous avez pu voir au cours de cet article que finalement, Terraform s’utilise relativement facilement et permet de déployer des copies d’une infrastructure à l’identique de manière répétable. Les templates sont faits pour être lisibles et faciles à éditer et la documentation de HashiCorp sur Terraform est complète et détaillée. En somme, Terraform est une fantastique corde à avoir à son arc pour toute problématique de déploiement d’infrastructure !